Shortcut to Nowhere: Demystifying
Deep Spurious Regression
📰 News
Abstract
Real-world regression often exhibits shortcuts: attributes that are spuriously correlated with continuous targets in training, yet unreliable under deployment shifts — regressing targets using such shortcuts may fail catastrophically at test time.
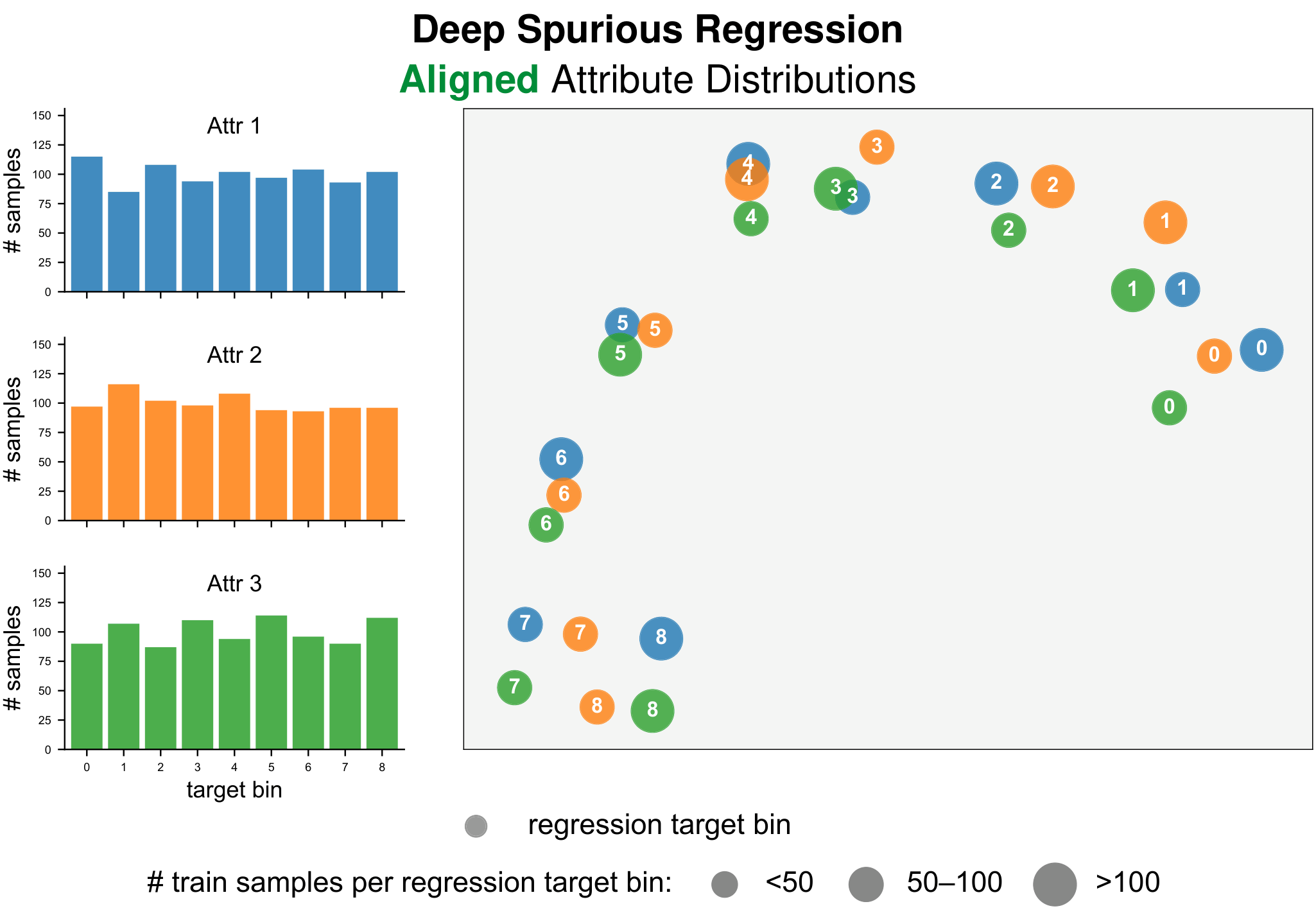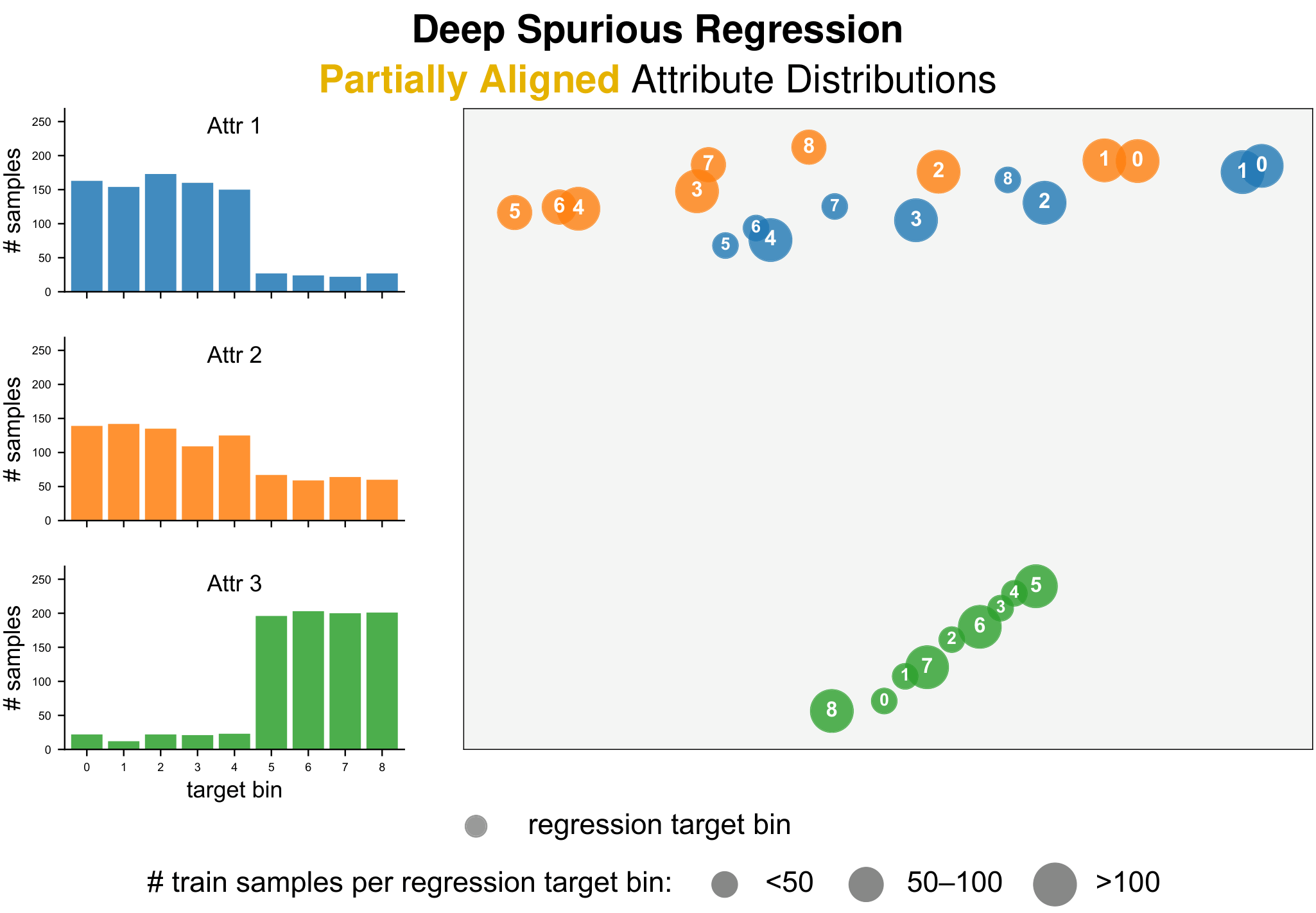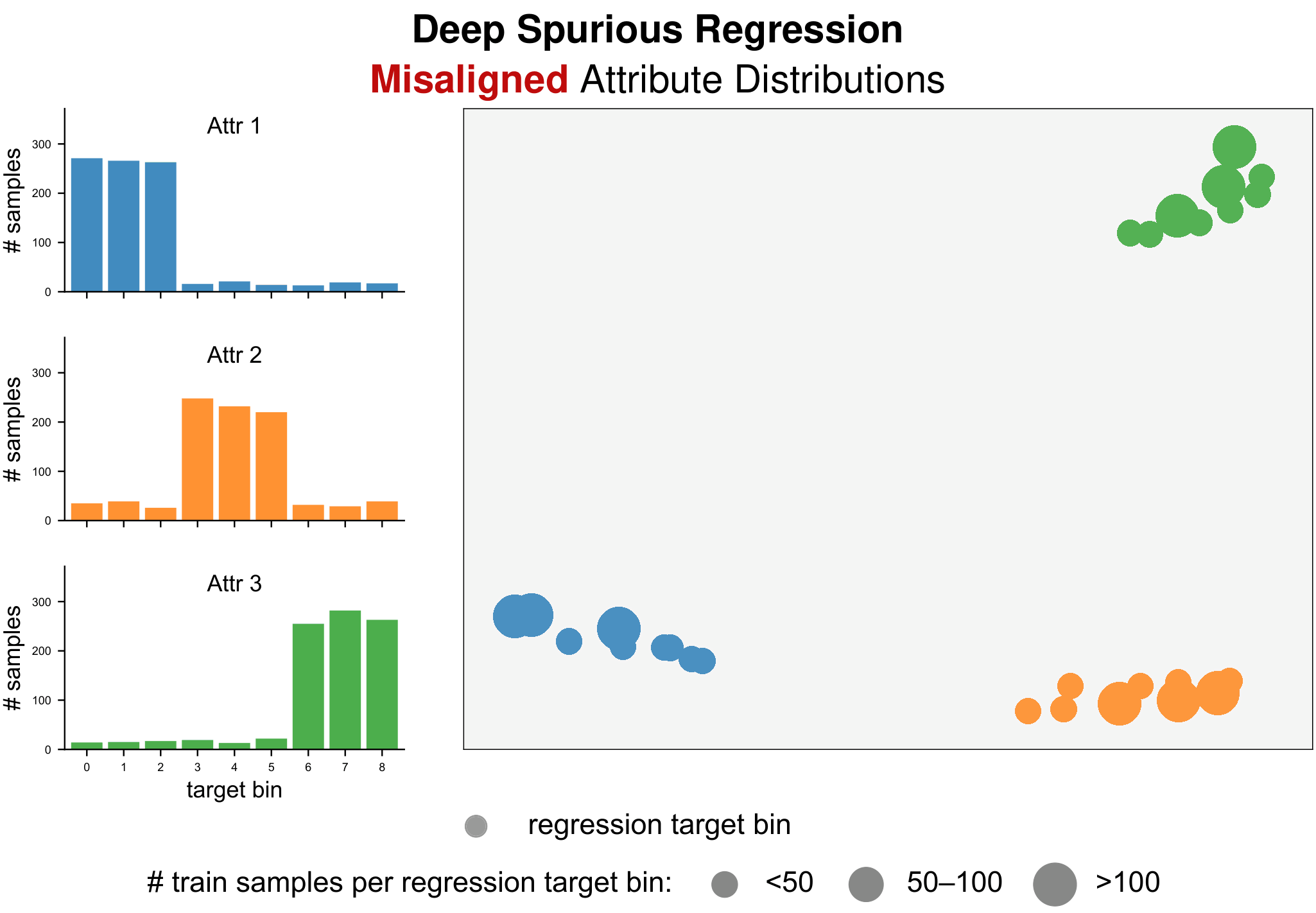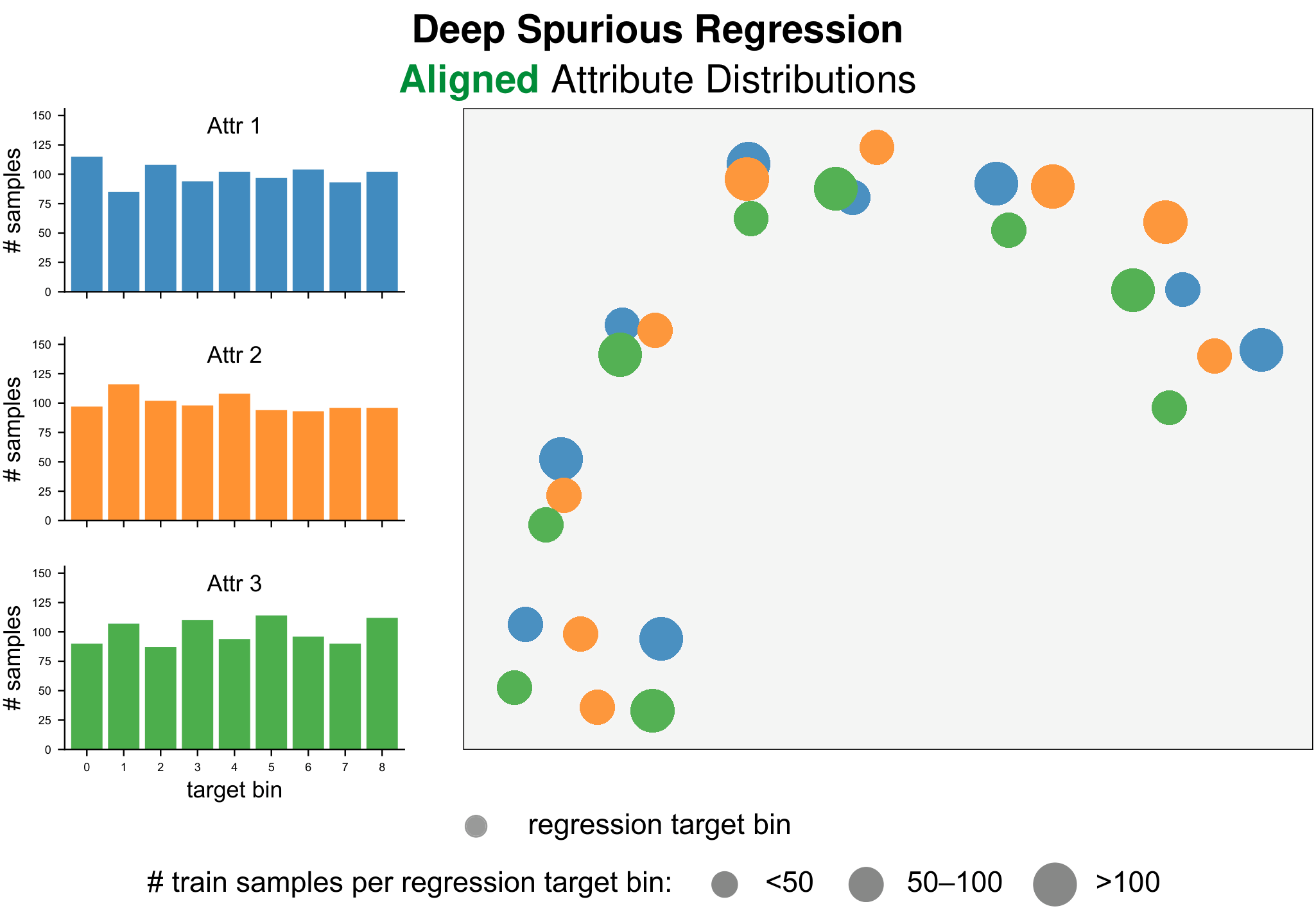
Existing studies on spurious correlations focus primarily on classification, where labels are categorical and groups are naturally defined. However, many real-world tasks require continuous prediction, where hard label boundaries or discrete group–label pairs do not exist. We define Deep Spurious Regression (DSR) as learning from regression data with attribute–label confounding, addressing continuous spurious correlations, and generalizing to all attribute–label combinations at test time.
Motivated by the intrinsic difference between classification and regression shortcuts, we propose to exploit the similarity among spurious attributes in both label and feature spaces, thereby accounting for nearby targets and related groups while calibrating both label and learned feature distributions across attributes. Extensive experiments on real-world DSR datasets spanning computer vision, environmental sensing, and LLM regression verify the superior performance of our strategies. Our work fills the gap in benchmarks and techniques for studying spurious correlations in continuous prediction.